
WEB3
por
Tatiana Revoredo
A era digital já nos acostumou a mercados que se desenvolvem rápido. Mas nada parece ter sido tão veloz quanto os modelos de linguagem. Executivos de negócios devem entender a fundo cinco fatores que podem diferenciar um player na nova corrida – antes de tomar suas decisões

Toda a animação em torno da IA generativa desde o lançamento do ChatGPT, em novembro de 2022, faz sentido. Empresas de capital de risco investiram em startups do setor, e corporações aumentaram o aporte em tecnologia na expectativa de automatizar muitos fluxos de trabalho – e economizar muito dinheiro.
Os primeiros estudos mostraram que a IA generativa pode, sim, trazer aumentos significativos à produtividade. Mas o que era esperado no começo desta história realmente aconteceu? Não, várias dúvidas permanecem no ar.
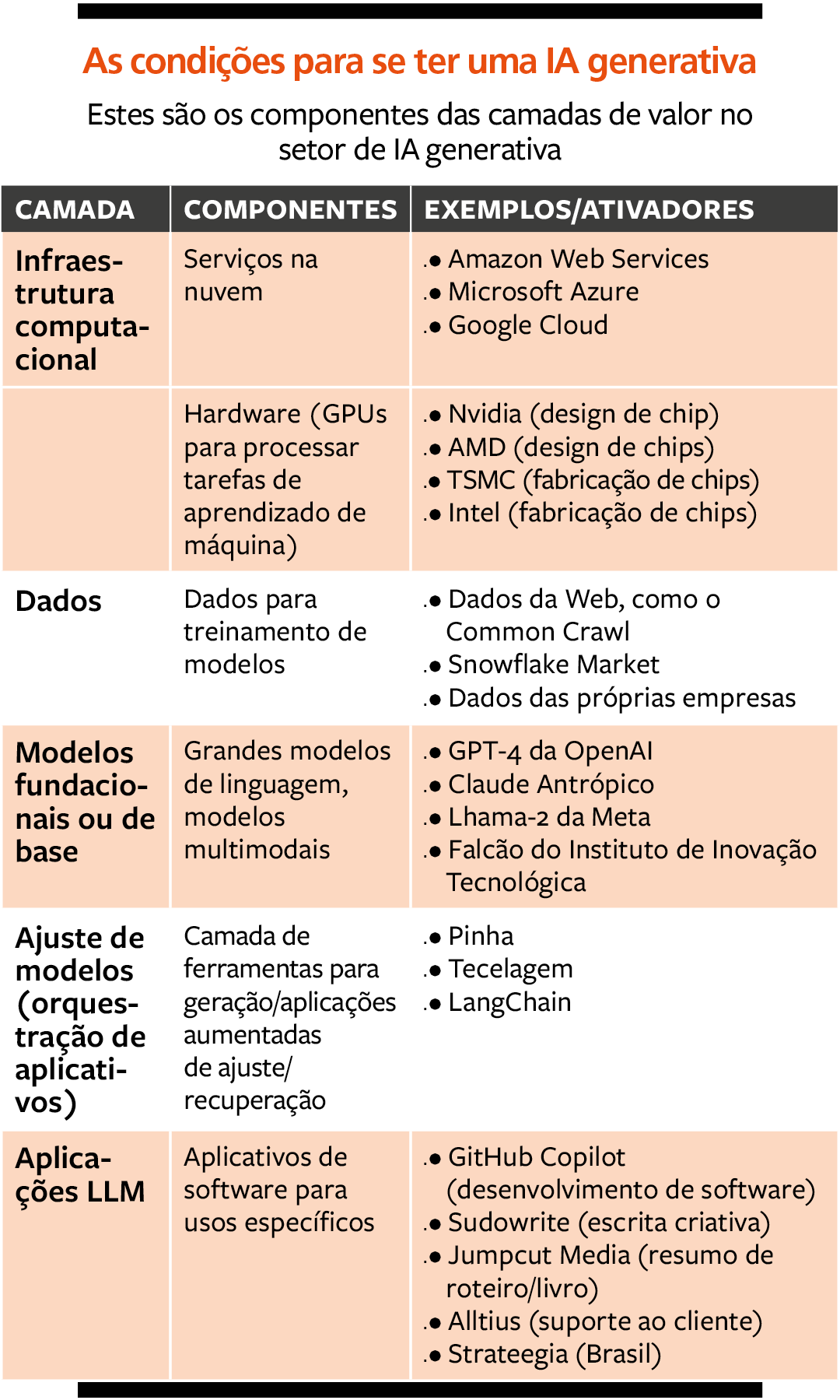
Primeiro, para tentar identificar o que poderia levar a uma diferenciação no novo contexto, e então responder à pergunta acima, analisamos cinco fatores relacionados com a IA generativa: infraestrutura computacional, dados, modelos fundacionais, modelos ajustados e aplicativos.
1. Infraestrutura computacional – Na base do que se precisa para a IA generativa está a infraestrutura computacional de unidades de processamento gráfico (GPUs, na sigla em inglês) de alto desempenho. É nelas que os modelos de machine learning são treinados e executados.
Para construir um novo modelo de IA generativa, uma empresa precisa de GPUs e outros hardwares relacionados para treinar e executar seu próprio grande modelo de linguagem (LLM, na sigla em inglês). Isso pode ter um custo proibitivo e ser contraproducente, uma vez que essa infraestrutura já está disponível por meio dos principais fornecedores de nuvem, como Amazon Web Services (AWS), Google Cloud e Microsoft Azure. No Brasil, há agora o Magalu Cloud, com a proposta de ser mais acessível.
2. Dados – Os modelos de IA generativa são treinados por grandes volumes de dados disponíveis na internet, vindos de fontes públicas ou privadas. Embora os desenvolvedores informem como o modelo foi treinado, eles não dão detalhes sobre a procedência das fontes usadas. Pesquisadores driblaram isso ao aplicar técnicas variadas para revelar as muitas fontes de dados usadas nos treinamentos.
3. Modelos fundacionais – São redes neurais treinadas com grandes volumes de dados, mas sem uma otimização para tarefas específicas – como elaboração de contratos jurídicos ou respostas a perguntas técnicas sobre um produto. Há modelos de código fechado, como o GPT-4, da OpenAI, e o Gemini, do Google, bem como modelos de código aberto, como o Llama 2, da Meta, e o Falcon 40B, do Technology Innovation Institute, instituição de Dubai, nos Emirados Árabes Unidos.
É possível entrar no mercado de IA generativa construindo um novo modelo de base. Mas os dados, os recursos financeiros e tecnológicos, bem como a experiência técnica necessários para criar e treinar modelos de alto desempenho, são uma barreira significativa. Por isso há tão poucos modelos de base de alta qualidade disponíveis no mercado.
4. Abordagens de ajuste de modelos – Os modelos de base são versáteis e trazem bons resultados em uma vasta gama de tarefas de linguagem, mas podem não ter o melhor desempenho para determinados contextos e tarefas. Para tanto, talvez seja necessário trazer dados mais específicos.
Para ajudar usuários a solucionar problemas técnicos com um produto, por exemplo, o LLM pode adotar algumas abordagens.
Abordagem RAG. Envolve a criação de um serviço que recupera trechos de informações relevantes para a pergunta do usuário final e anexa as informações à instrução (prompt) enviada ao modelo básico.
Isso envolve escrever um código que extrai a informação necessária do manual do produto que esteja mais relacionada à dúvida e instruir o LLM a responder à pergunta do usuário com base nesse trecho de informação. A abordagem se chama “geração aumentada de recuperação” (ou RAG, na sigla em inglês). Os gastos para essa abordagem incluem os custos de API do modelo escolhido, que aumentam com o tamanho do prompt de entrada e o tamanho da saída do LLM. Assim, quanto mais informações dos manuais do produto forem enviadas ao LLM, maior será o custo.
Ajuste fino no modelo. Em vez de alimentá-lo com contextos (os trechos do manual do produto) por meio de prompts, essa abordagem retreina a rede neural do modelo de base usando dados específicos do domínio. Esse caminho acaba sendo ainda mais caro.
A abordagem RAG acaba sendo mais fácil de ser implementada e não tem os custos de computação de retreinamento. Por outro lado, a abordagem de ajuste fino, embora mais cara no início, tem o potencial de produzir melhores resultados e, uma vez concluída, está disponível para uso futuro sem a necessidade de se trazer o contexto de cada consulta, como é o caso do RAG.
5. Aplicativos de LLM – Um modelo de base ou um modelo ajustado servem para a criação de serviços para usos específicos. Startups já criaram aplicativos para elaborar contratos (Evisort), resumir livros e roteiros de filmes (Jumpcut) ou responder a perguntas para solução de problemas técnicos (Alltius). No Brasil, há até uma plataforma que facilita esse processos para pessoas mais ligadas aos negócios que à tecnologia, chamada Strateegia, ligada à consultoria TDS.company, que visa tornar mais intuitivo esse desenvolvimento.
Esses aplicativos têm preços semelhantes aos aplicativos tradicionais de software como serviço (com taxas mensais de uso). Seus custos marginais estão principalmente ligados a taxas de hospedagem na nuvem e taxas de API de modelos básicos.
Nos últimos meses, gigantes da tecnologia e investidores fizeram pesados investimentos em produtos do tipo. Surgiram novos modelos fundacionais, e empresas criaram modelos específicos para resolução de tarefas, treinados com dados proprietários na esperança de obter uma vantagem sobre as concorrentes. Em cima disso, milhares de startups estão construindo aplicativos.
Quais players podem ter maior rendimento sobre esses investimentos? Dezenas de modelos de base foram lançados nos últimos meses, e muitos podem oferecer desempenho comparável ao dos modelos gerais mais populares. Ainda assim, acreditamos que o mercado de IA generativa pode se consolidar de maneira semelhante ao de serviços em nuvem, dominado por Amazon, Google e Microsoft. Há três explicações para o fato de a maioria das startups de infraestrutura ter falhado (ou ter sido comprada por rivais maiores) – e elas também se aplicam a modelos de linguagem.
1 Custo e capacidade – Criar, sustentar e manter atualizada a infraestrutura tecnológica de alta qualidade é algo que exige muito, especialmente no caso dos LLMs. O custo das GPUs, cuja demanda está superior à oferta, também impacta bastante.
Por exemplo, somente na última rodada de treinamento, o custo de infraestrutura do modelo PaLM de 540 bilhões de parâmetros do Google ficou entre US$ 9 milhões e US$ 23 milhões, segundo uma estimativa externa. Os investimentos da Meta em GPUs em 2023 e 2024 são estimados em mais de US$ 9 bilhões. Além disso, como vimos, a construção de um modelo de base requer acesso a grandes quantidades de dados, bem como simulações e experiência significativas, o que pode sair muito caro.
2 Comportamento da demanda – À medida que o ecossistema em torno dessas infraestruturas cresce, também crescem as barreiras para novos participantes do setor. Pegue o PromptBase, um mercado online de prompts para alimentar LLMs. O maior número de prompts disponíveis é para o ChatGPT e os geradores de imagem Dall-E, Midjourney e Stable Diffusion. Um novo LLM pode ser atraente do ponto de vista da tecnologia, mas se os usuários tiverem um conjunto de prompts que funcionam bem no ChatGPT e nenhum prompt comprovado para esse novo LLM, é provável que eles permaneçam no ChatGPT.
Enquanto isso, o número de usuários e aplicativos segue crescendo: o ChatGPT, com sua enorme base, atrai desenvolvedores para construir plugins em cima dele. Fora que os dados de uso do LLM criam um ciclo de feedback que permite que os modelos melhorem. Em geral, os mais populares melhorarão mais rápido do que os menores porque têm mais dados de usuários para trabalhar – e essas melhorias trazem ainda mais usuários.
3 Economia de escala – LLMs com grandes bases de clientes têm um custo por uso menor do que LLMs iniciantes. Esses fatores incluem a possibilidade de negociar melhores taxas de fornecedores de GPUs e provedores de serviços em nuvem.
Por todas essas razões, embora novos modelos de base sejam lançados regularmente, acreditamos que o mercado se consolide em torno de poucos e grandes nomes.
As empresas que desejam entrar no mercado de serviços de IA generativa terão de decidir se devem construir aplicativos sobre modelos de base de terceiros, como o GPT-4, ou criar e hospedar seus próprios LLMs (construindo em cima de alternativas de código aberto ou treinando-os do zero).
Criar em cima de LLMs de terceiros pode trazer ameaças à segurança, como a exposição potencial de dados proprietários. Esse risco é parcialmente mitigado pelo uso de provedores confiáveis, que podem garantir que os dados dos clientes permaneçam confidenciais e não sejam usados para treinar e melhorar seus modelos.
Uma alternativa é aproveitar LLMs de código aberto, como Llama 2 e Falcon 40B, sem depender de provedores de terceiros. O apelo dos modelos de código aberto é que eles fornecem às empresas acesso completo e transparente, geralmente são mais baratos e podem ser hospedados em nuvens privadas.
No entanto, os modelos de código aberto estão atrasados em termos de desempenho em tarefas complexas, como geração de código e raciocínio matemático. Além disso, hospedá-los exige habilidades técnicas internas e conhecimento, enquanto usar um LLM hospedado por terceiros pode ser tão simples quanto se inscrever em um serviço, usar as APIs do provedor e acessar suas funcionalidades. Os provedores de nuvem têm, cada vez mais, disponibilizado modelos de código aberto, dando acesso por meio de uma API para resolver tal preocupação.
A última alternativa é construir seus próprios modelos do zero. A questão do LLM privado versus público depende de uma empresa ter os recursos para implantar, gerenciar, manter e melhorar continuamente essa tecnologia. Os fornecedores se posicionam para ajudar com essas tarefas não triviais, mas o apelo sem complicações de encontrar tudo à mão nos grandes provedores de infraestrutura de nuvem é bem atraente.
O desempenho de um LLM, assim como o seu valor, é determinado pela arquitetura da rede neural (o modelo) e pela quantidade e qualidade dos dados em que ela é treinada. Os modelos transformadores requerem grandes quantidades de dados. Os de alto desempenho – que geram conteúdo preciso, relevante, coerente e imparcial e são menos propensos a “alucinar” (oferecer informações equivocadas ou tendenciosas) – operam em uma escala de mais de 1 trilhão de tokens de dados da internet e bilhões de parâmetros.
O token é uma unidade básica de texto para um LLM, geralmente uma palavra ou subpalavra. Já os parâmetros são variáveis de um modelo de aprendizado de máquina que podem ser ajustadas por meio de treinamento.
Os maiores LLMs têm o melhor desempenho em uma ampla variedade de tarefas. Mas a qualidade e a distinção dos dados podem ser igualmente importantes para a eficácia dos LLMs, e os modelos treinados ou ajustados em dados específicos de um domínio podem superar modelos maiores, mais generalistas, em tarefas especialistas para domínios específicos. Por essa razão, as organizações que têm acesso a grandes volumes de dados de alta qualidade em domínios específicos podem ter uma vantagem sobre outros players na criação de modelos feitos especialmente para seus setores.
Por exemplo, a Bloomberg aproveitou seu acesso a dados financeiros para construir um modelo especializado. O BloombergGPT tem 50 bilhões de parâmetros, bem menor que o ChatGPT-3.5, que tem cerca de 475 bilhões, mas mesmo assim os primeiros testes mostraram que o LLM da Bloomberg superou o da OpenAI em uma série de tarefas financeiras.
Ambos os modelos são treinados em grandes conjuntos de dados (700 bilhões de tokens para o BloombergGPT e 500 bilhões para o ChatGPT-3.5). Só que mais de 52% do conjunto de dados de treinamento do BloombergGPT consiste em fontes financeiras selecionadas, o que lhe dá uma vantagem em tarefas específicas desse domínio.
Dito isso, um estudo recente mostrou que o GPT-4, com prompts aprimorados, superou o BloombergGPT para tarefas financeiras simples. Atribuímos isso ao maior tamanho do modelo do GPT-4 (que teria mais de 1 trilhão de parâmetros).
Em suma, embora os modelos construídos com dados específicos do domínio possam oferecer um forte desempenho com modelos menores e mais baratos, treiná-los não é algo que tenha fim e exigirá investimento contínuo, dado que os modelos generalistas estão em constante crescimento e melhoria. Usuários de outros setores com dados específicos de domínio, como seguros, mídia e cuidados de saúde, provavelmente também se beneficiarão de LLMs especializados.
As empresas que criam aplicativos em cima de modelos fundacionais enfrentam um dilema: a concorrência pode replicar a funcionalidade de seus aplicativos usando os mesmos modelos de base. Na falta de uma diferenciação pelos modelos ou pelos dados, as empresas precisarão se destacar na interface, onde a inteligência da máquina encontra o usuário.
Acreditamos que a vantagem, aqui, está em aplicativos desenvolvidos para um público bem definido. É o caso do GitHub Copilot, usado por 100 milhões de desenvolvedores mundo afora. Essa enorme quantidade de gente oferece uma vantagem distributiva sobre startups que trabalham em produtos de geração de código semelhantes. A análise de uma base de usuários tão grande também ajuda o GitHub a melhorar o modelo e integrá-lo em sua plataforma de desenvolvimento de software.
Há um porém. As organizações enfrentarão o desafio de equilibrar o aprimoramento do modelo de IA com as preocupações com a privacidade do usuário. Um exemplo é a indignação pública que levou o Zoom a mudar os seus termos de uso, que permitiam à empresa utilizar conteúdo de clientes para treinar sua IA.
Dessa forma, as empresas de tecnologia tenderão naturalmente para a integração vertical, em que a criadora do LLM também é dona do aplicativo. O Google já está integrando seus recursos de LLM ao Google Docs e ao Gmail, assim como a Microsoft está fazendo com seus produtos, por meio de sua parceria com a OpenAI.
Mesmo assim, organizações em domínios específicos que não têm seus próprios LLMs podem ter sucesso criando aplicativos voltados para sua base de usuários. Elas podem aproveitar seu acesso privilegiado a certos conteúdos para agrupar novos recursos usando IA e colocá-los nas mãos dos clientes mais rápido do que as concorrentes.
Em outras palavras, se houver um mercado grande e competitivo de LLMs com recursos equivalentes, os aplicativos que possuem uma base de usuários grande e fiel podem tirar mais proveito da IA generativa. É uma vantagem relevante em relação a novos operadores, e sem precisar de um LLM próprio.
É preciso pensar muito sobre quais tarefas complexas específicas podem ser abordadas usando dados proprietários. Essa propriedade permitirá que uma empresa entregue algo único aos seus clientes.
Há casos em que a funcionalidade dos serviços e produtos habilitados para IA de uma empresa é facilmente replicada pelas concorrentes, seja porque elas têm dados semelhantes ou porque LLMs generalistas podem alcançar recursos semelhantes. Nessa situação, a vantagem competitiva precisa estar na capacidade de implantar imediatamente esses aplicativos em uma grande base instalada e treiná-los com enormes quantidades de dados de clientes.
Empreendedores que constroem startups sem acesso a dados proprietários ou a uma grande base instalada terão que lidar com essa situação para driblar sua desvantagem. Eles precisarão construir em cima de modelos de uso geral de grande porte e que possam ser ajustados, pelo menos em tarefas específicas mais simples, para construir seus produtos e serviços no começo. Terão ainda que contar com sua agilidade e com a inércia dos demais para gerar um lançamento mais ágil do que os players mais poderosos, porém mais lentos.
Um grande número de criadores de conteúdo levantou preocupações sobre direitos autorais e propriedade intelectual. O New York Times entrou com um processo contra a OpenAI alegando que ela usou o conteúdo de sua propriedade para treinar seus modelos e criar produtos. Outras empresas, autores e programadores também processaram donos de LLMs por motivos semelhantes.
A OpenAI argumentou que os modelos de treinamento sobre conteúdo protegido por direitos autorais são aceitos pela lei. Mas ela reconheceu a necessidade de se estabelecer novas formas de contrato para esse uso.
Independentemente de como esses processos serão resolvidos, o uso de propriedade intelectual para treinamento de LLMs provavelmente será algo mais fácil de lidar para as empresas que já estão estabelecidas em IA generativa. Google, Microsoft e Meta têm recursos para lutar contra reivindicações de direitos autorais, assinar contratos de licenciamento com criadores de conteúdo e indenizar autores com reivindicações do tipo.
Aqueles que estão procurando criar um novo modelo de base podem ter dificuldades para bater de igual para igual com os grandes nomes do mercado em termos de desempenho. Para poder competir em outros fatores, o negócio é construir o ecossistema, bem como as ferramentas para cada item relativo à IA. Se uma organização tiver dados específicos de um domínio em grande escala, um LLM próprio permitirá sua diferenciação daqueles de uso geral.
As empresas que buscam experimentar e, ao final, integrar a IA generativa em seus fluxos de trabalho ou produtos, precisam rapidamente ter clareza sobre os usos e tarefas que são bons candidatos para um teste. Alguns dos critérios para isso são as respostas a três perguntas:
1 Esse uso é regulamentado? Empresas em setores altamente regulamentados, como saúde e serviços financeiros, podem estar sujeitas a normas muito estritas, que tornam inviável para elas planejar o desenvolvimento e o lançamento de produtos em pouco tempo. Dado o rápido avanço e as mudanças na IA generativa, é importante que os testes sejam rápidos. Logo, ciclos de produtos de vários anos não são simulações ideais para IA generativa hoje.
2 Os erros são gerenciáveis? Resultados errados ou tendenciosos são inevitáveis com a IA generativa. Há muitos exemplos de respostas “alucinadas” de LLMs, bem como erros e vieses em texto e imagens gerados por IA. Além disso, há casos de problemas de confidencialidade de dados decorrentes do uso corporativo de modelos de IA generativa de terceiros. Desenvolver competência interna na detecção e correção de falhas e garantir a segurança e a privacidade de dados será crucial.
3 Você tem dados exclusivos e conhecimento de domínio para habilitar e controlar o ajuste fino ou RAG? Se um aplicativo for apenas uma interface desenvolvida para interagir com os LLMs da OpenAI (os chamados “wrapperGPT”), ele não resolverá desafios específicos do setor ou da empresa. Nesses casos, aproveitar dados proprietários e primários será fundamental.
Após identificar um uso apropriado, a próxima etapa é fazer (ou comprar) um modelo e/ou aplicativos, levando em conta as estratégias do fornecedor e a própria maturidade tecnológica da organização. Construir uma equipe interna com consciência das tecnologias relevantes e das métricas para avaliar o ROI é essencial para tomar boas decisões.
É UMA TECNOLOGIA QUE ESTÁ SE DESENVOLVENDO MUITO RAPIDAMENTE. As escolhas de uma empresa de fazer ou não seus próprios modelos deve levar em conta sua capacidade não apenas de construí-los, mas também de continuar a aperfeiçoá-los para acompanhar o ritmo do mercado.
Principais takeaways
Nenhuma onda tecnológica provocou tanto barulho como a da inteligência artificial generativa. Isso requer que os líderes de uma organização com responsabilidades de negócios consigam entender a relação custo/benefício de cada escolha a ser feita na hora de tomar decisões de investimento e de priorização.
Este artigo se concentra nos cinco fatores que podem criar diferenciação em IA generativa para as empresas, posicionando-se e tirando dúvidas sobre cada um deles: infraestrutura computacional, dados, modelos fundacionais (ou modelos de base), abordagens de ajuste e aplicativos.
Por exemplo, em infraestrutura computacional, ponderam-se os altos custos de aquisição e manutenção de hardware (basta pensar em GPUs de alto desempenho) para recomendar serviços.








