

COBRANDED
por
MIT SMR Brasil + Meeg
Uma abordagem colaborativa para treinar modelos de IA pode produzir melhores resultados, mas requer encontrar parceiros que tenham dados complementares aos seus. Veja como explorar esse “learning” federado, seja para machine learning ou qualquer outro tipo de inteligência artificial


Hoje em dia, implantar inteligência artificial no negócio não é garantia de vantagem competitiva. O que realmente diferencia as empresas é o acesso a dados diversos, extensos e de alta qualidade. Eles, sim, aprimoram o desempenho do sistema de IA em comparação com o da concorrência.
O problema é a preocupação com a privacidade. Isso pode limitar o uso de dados exclusivos e relevantes para análise.
Dá para reduzir esse empecilho por meio do treinamento federado em dados. Essa técnica, em combinação com um tipo especial de criptografia, permite que um modelo de IA ou qualquer outro tipo de algoritmo seja treinado usando dados de vários servidores descentralizados controlados por diferentes organizações.
Tudo é feito respeitando a privacidade dos indivíduos ou empresas. Simplificando, no treinamento federado não são os dados que são enviados aos algoritmos, mas os algoritmos que vão ao encontro dos dados.
Foi assim que a Zurich Seguros conseguiu melhorar um algoritmo preditivo com dados da Orange, telecom sediada na França. Usando uma plataforma de mercado dedicada a treinamento federado, a Zurich treinou seu algoritmo e aprimorou seus recursos preditivos sem que a Orange precisasse liberar nenhum dado.
A colaboração levou a uma melhoria de 30% nas previsões do sistema de IA, o que se traduziu em um aumento significativo de receita para a Zurich. Para a Orange, representou uma nova maneira de monetizar seus dados e, ao mesmo tempo, garantir privacidade.
Aplicações reais de treinamento federado em dados estão surgindo rapidamente. Por exemplo, a unidade de crédito de um grande banco usou esse modelo para ajustar seu algoritmo de previsão de inadimplência de empréstimos, utilizando dados de propriedade de uma das maiores empresas globais de telecomunicações. Ela melhorou a precisão da previsão em cerca de 10%.
O valor de tais colaborações vem da capacidade de treinar sistemas de IA em conjuntos muito mais ricos de dados do que qualquer empresa poderia montar por conta própria. Para fazer isso, elas precisam identificar parceiros cujos dados possam ser usados em um treinamento federado.
Parece mais lógico que empresas de diferentes setores colaborem umas com as outras com mais facilidade do que empresas do mesmo setor. Mas o treinamento federado funciona melhor quando há cooperação dentro dos setores, inclusive entre concorrentes diretos.
É o que acontece em alguns hospitais privados. Seus departamentos de patologia, que têm lutado para compilar conjuntos de dados consistentes por conta própria, decidiram se unir.
Eles treinam um algoritmo de diagnóstico compartilhado em uma combinação de seus respectivos conjuntos de dados – por exemplo, imagens de tecido físico que devem ser analisadas em busca de doenças. Como resultado, os hospitais participantes se beneficiam de um algoritmo com desempenho muito superior no fornecimento de informações valiosas.
A colaboração pode resultar em um novo tipo de modelo de negócios orientado por dados para hospitais. As ações de propriedade do algoritmo são determinadas com base na contribuição dos dados de cada hospital para sua precisão.
Esse algoritmo também pode ser comercializado e alugado a terceiros, como outros hospitais. Tudo isso sem compartilhar dados sensíveis com concorrentes.
Já o setor financeiro adota outra abordagem, que permite que organizações concorrentes aproveitem os benefícios do treinamento federado em dados. Usando um sistema chamado criptografia homomórfica multipartidária, cada banco pode verificar se um cliente foi apontado por um concorrente como sendo não confiável ou problemático.
Isso reduz o custo do processo “conheça seu cliente”, que atualmente representa cerca de 3% dos custos operacionais dos bancos no mundo todo. Além disso, gera uma melhor experiência para o cliente.
Vários hospitais estão usando o mesmo tipo de plataforma de computação criptografada para treinar com segurança um modelo de machine learning para diagnósticos em dermatologia. Isso é feito com base em vários conjuntos de dados localizados em diferentes países.
Já outros usam a técnica para produzir estatísticas descritivas, permitindo extrair intervalos de referência personalizados para pacientes saudáveis e doentes com base nos dados mais recentes disponíveis. Com isso em mãos, os médicos trabalham com limites personalizados para diagnosticar os pacientes sem ter que depender de uma referência única para o diagnóstico.
O treinamento federado é amigo da privacidade – e isso faz toda a diferença quando o assunto é IA
Ao avaliar com quais organizações externas fazer parceria, os líderes de negócio devem observar a natureza dos dados que sua própria empresa poderia fornecer para colaborar. Eles devem conter grande número de amostras (clientes, pacientes, apólices de seguro etc.) e grande número de itens (variáveis) dentro de cada amostra.
O número de amostras e o número de itens por amostra são as duas dimensões pelas quais as organizações podem se beneficiar do uso de técnicas de treinamento federado. O treinamento federado horizontal envolve o aumento do número de amostras com as quais o modelo é treinado. Já o treinamento federado vertical trata do aumento do número de itens que o modelo analisa para cada uma das amostras.
Essas duas dimensões dão origem a quatro situações em que os líderes podem se encontrar ao explorar o cenário de treinamento federado. Veja mais no quadro a seguir.
Os dados que uma organização tem e pode usar para treinar um sistema de IA ou para resolver um problema de análise de qualquer tipo podem ser ruins/pobres, horizontais, verticais ou ricos/enriquecidos. O rótulo que se aplica é determinado com base no número de amostras e no número de recursos dentro de cada amostra

Dados verticais são aqueles conjuntos em que há um grande número de amostras, mas com poucos itens em cada uma. Eles precisam do chamado treinamento vertical para serem enriquecidos.
Já os dados horizontais têm um pequeno número de amostras, mas muitos itens em cada uma. Eles requerem treinamento horizontal para enriquecer os dados.
Por fim, dados ruins são os conjuntos em que o número de amostras é baixo, assim como a quantidade de itens em cada uma delas. Esses demandam mais trabalho.
Os líderes de negócio que desconhecem as propriedades, que diferenciam esses quatro tipos de dados, correm riscos. Eles podem estabelecer colaborações que fazem com que dados ruins virem horizontais ou verticais, mas não sejam enriquecidos.
Começar com dados ruins e terminar com dados verticais ou horizontais pode parecer atraente, mas pode não significar um melhor desempenho. Por exemplo, um hospital transforma seus dados ruins em verticais, incorporando informações sobre muito mais pacientes sem adicionar novos recursos relevantes a partir deles.
Nessa situação, ele pode não ser capaz de melhorar o poder preditivo de sua ferramenta de IA de diagnóstico. Isso porque ela não será capaz de isolar os itens que se correlacionam positivamente com a doença.
Da mesma forma, passar de dados ruins para dados horizontais também pode não gerar vantagem, uma vez que a IA precisa de variação suficiente nos itens relevantes. Só assim ela encontrará padrões significativos e valiosos para o negócio.
Assim, ao considerar se devem colaborar com uma organização externa em um projeto de aprendizado federado, os líderes precisam se perguntar: “Qual é o status dos meus dados – ruins, verticais, horizontais ou enriquecidos?” Essa pergunta pode ser respondida avaliando as dimensões vertical e horizontal dos dados.
Nos casos de uso de bancos, seguros, telecomunicações e assistência médica discutidos neste artigo, os colaboradores migraram de dados horizontais ou verticais para dados avançados graças ao treinamento horizontal ou ao vertical
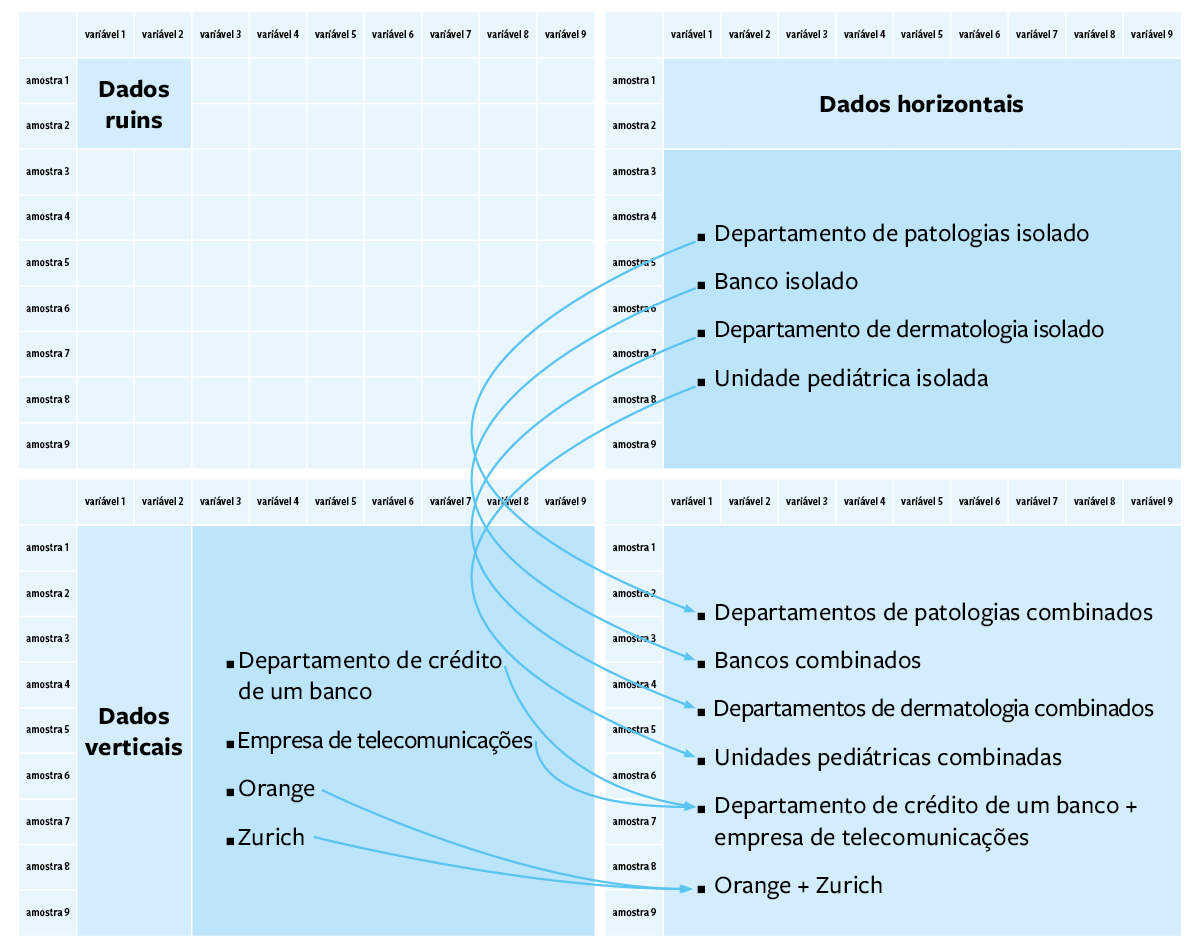
Nos casos que vimos neste artigo, as organizações passaram de dados horizontais ou verticais para dados enriquecidos graças ao treinamento horizontal ou vertical. Vejamos como cada um funciona.
O número de observações na amostra e o quanto ele é representativo de toda a população dão a dimensão vertical. Se você responder “sim” à pergunta “Todos os segmentos da população ou realidade estão representados na amostra?”, então os dados são considerados verticais.
A dimensão horizontal, por sua vez, é avaliada quando consideramos se as variáveis (ou itens) disponíveis sobre cada uma das observações da amostra são suficientes para explicar o comportamento de uma única observação. Pergunte-se se dá para entender como os indivíduos da amostra se comportarão ao considerarmos todas as variáveis registradas. Em caso positivo, os dados são horizontais.
Quando você conseguir um duplo “sim”, os dados são considerados enriquecidos. Se a resposta for “não” às duas perguntas, aí é sinal de dados ruins.
Caso os dados sejam verticais, procurar organizações parceiras em outros setores pode ser o caminho certo a seguir, já que as empresas que oferecem serviços diferentes registram dados diferentes sobre eles. Foi o que ocorreu na parceria Orange-Zurich: a empresa de telecomunicações entrou com dados sobre a comunicação e a mobilidade dos consumidores, enquanto a seguradora levantou informações sobre aversão a risco e eventos significativos da vida dos clientes.
Agora, se os dados forem horizontais, procurar organizações do mesmo setor pode ser o melhor caminho. Nesse caso, você precisará de mais amostras para enriquecer o conjunto de dados.
Se os dados forem ruins, a organização precisa começar pelo processo de registro. Estudar os dados que outras empresas já computaram e aqueles que podem ser complementares a uma ou mais dessas organizações, enriquecendo os conjuntos de dados verticais ou horizontais, é a estratégia certa.
Se os dados forem enriquecidos, a empresa já está em posição de aproveitar o poder da IA por meio de seu próprio conjunto de dados. Mas o aprendizado federado ainda tem algo a oferecer – ou seja, a oportunidade de monetizar esses dados enriquecidos, contribuindo para o treinamento de sistemas de IA em outras organizações, mantendo a propriedade total de seu próprio conjunto. É isso que a Mayo Clinic, organização americana de serviços e pesquisas médicas, está fazendo por meio do Solutions Studio, um programa que oferece acesso a dados globais federados não identificados.
Depois que os líderes identificarem as organizações que têm dados complementares, há outros obstáculos, incluindo a conversão de dados não estruturados em um formato utilizável. Dados não estruturados de fontes como arquivos pdf, relatórios manuscritos e digitalizados ou até cópias de fax precisam ser organizados e legíveis por máquina.
Nomenclaturas díspares podem ser outro problema. Organizações diferentes costumam usar termos diversos para se referir à mesma variável. Logo, os catálogos de dados das organizações colaboradoras provavelmente precisarão ser sincronizados, o que pode estender o tempo necessário para treinar a IA.
O desafio mais crítico, no entanto, são as pessoas e seus medos. A resistência à colaboração com organizações externas, particularmente concorrentes, pode dificultar a exploração e a implantação do aprendizado federado.
É crucial, portanto, que as pessoas das várias organizações colaboradoras se envolvam umas com as outras ao montar arquiteturas federadas de aprendizado de máquina. Isso é verdade para qualquer processo de digitalização, mesmo dentro de uma única empresa, mas é ainda mais importante no contexto da aprendizagem federada.
Resta saber como escolher as organizações com as quais colaborar para treinar seus modelos de IA. Acreditamos haver seis fatores principais que os líderes de negócio precisam considerar:
AS ORGANIZAÇÕES QUE BUSCAM DESEMPENHO DE DESTAQUE precisam treinar e ajustar seus sistemas de IA com dados proprietários. O aprendizado federado permite que uma empresa faça isso usando algo que, até outro dia, parecia irreal: com dados de parceiros externos ou até mesmo de concorrentes.








